Background Jobs in .NET with Hangfire
Hangfire is a job scheduling framework for .NET which provides a simple way to schedule and execute background tasks. It is a free and open source project under the Lesser GNU public license. I setup a demo project on Github based on which I will go over some of the core concepts of Hangfire and some intermediate level additions, which helped us coming quite far with the free version of the tool.
Thus, I'm not delving into the paid options Hangfire Pro and Hangfire Ace. As far as I understand, they contain some quality-of-life job handling extensions, which aren’t required to set up a stable system. The most interesting feature would be the support for a Redis storage solution contained in the Pro package.
In this post I will be discussing some patterns we found useful running Hangfire as a distributed background job framework with SQL Server.
Overview
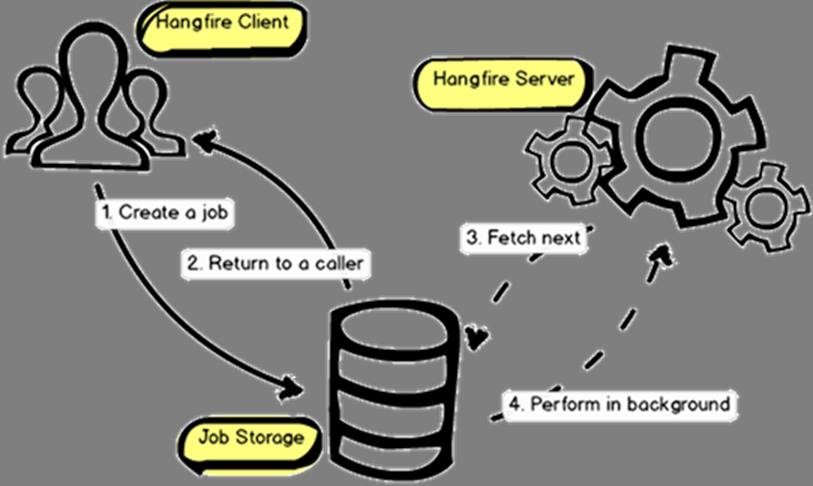 |
|---|
| Source: Documentation — Hangfire Documentation |
Hangfire basically consists of three components: Client, server, and storage. Clients schedule jobs by writing serialized job method declarations to storage, divided into job queues. Servers regularly poll their respective queue(s) and execute scheduled jobs based on the number of workers they’re configured to use as well as available threads on the host.
Recurring jobs can be enqueued separately by cron expressions.
Dashboard
To get an overview what is currently going on in a specific storage, Hangfire provides a dashboard view. There you can see the servers listening on the storage the dashboard is connected to, the scheduled recurring jobs and the currently executing jobs.
The dashboard can also interact with jobs, e.g. (re-) trigger them. To do this, it needs access to the assemblies containing the jobs. For a read only variant it is otherwise not required though and the job identifier will always be displayed.
 |
|---|
| View: Recurring Jobs |
 |
|---|
| View: Executing Jobs |
 |
|---|
| View: Server |
 |
|---|
| View: Usage and History |
In the demo project, this can be tried by running the Hangfire.Dashboard project while having the database connection string pointing to the same SQL server the Hangfire.Runner project is using.
Since the dashboard simply integrates with ASP.NET, it can easily be enhanced. E.g. we could add additional endpoints, which use a Hangfire client instance to interact with the job storage.
Server
On application start up the background service gets all implementations of the IGenericJob interface for simplicity. It then loads some configurations, checks which jobs to schedule or update and which to remove based on their identifier. Finally, it instantiates a Hangfire server with a custom job activator.
Our Use Cases
For better understanding where we are coming from, I want to briefly describe our most frequent use case.
Usually we have a recurring job, which checks how much work must be done and splits up the work in batches. It then schedules One-time jobs as workers to process a batch each.
The scheduling job must not run in parallel while the workers absolutely should, given enough work. Also, if any job fails, we don't want an automatic retry with the exact same parameters. We have other recovery processes depending on the state of work in a failed batch, e.g. recurring clean up jobs.
Run at Startup and Turn On
Two configurations have proven particularly useful in any job. On one hand a “run at startup” configuration. Some jobs profit from being run as soon as the service restarts, especially directly after a new release installation. While for others it’s better to not disturb their schedule. To do this, the background service does the normal scheduling and afterwards checks if a job should be triggered immediately.
On the other hand, we placed a simple “turn on” gate in front of every job. With it, we can deactivate jobs in a configurative manner. We do this by inheriting from an abstract job class, which checks this setting before every run.
In the demo project these are set in the appsettings.json, but of course, these settings can come from anywhere one has preferably easy access to.
Custom JobActivator for Dependency Injection
To be able to use dependency injection in the jobs instantiated by Hangfire, we use a simple, custom activator which passes the current container to the ActivatorUtilities to create instances.
Hangfire provides a UseActivator extension for this.
Clean Up
Recurring jobs which should be removed can be managed in multiple ways. We wanted to do this by configuration. So, on startup the background service checks which jobs are available in the Hangfire database and compares them with the current configurations.
The quickest way I found to do this, was to directly query the Hangfire storage for the currently available job keys. This relies on the internal structure of Hangfire keys, which is not ideal. On the other hand, if we try to go via the provided JobStorage API, the client tries to deserialize the jobs first, which may not be an option in a multi-server setup because not every server needs to have every assembly available. I have also answered a StackOverflow question on this topic solving this using EntityFramework.
We could reload this scheduler configuration regularly in another job or simply use the "turn on" configuration to turn off the job until next restart. For scheduling new jobs, a new assembly build is required anyway.
7-Part Cron Expressions
Additionally, Hangfire supports 7-part cron expressions, which means even the seconds are configurable. This can help with load balancing so not all your recurring jobs running in regular intervals try to run at the zero second mark.
Job Filters
Hangfire provides a way to customize job behaviour by applying filters to the jobs you want to run. You can either apply them globally by using the useFilter configuration method or add the corresponding attributes to the actual method which gets executed.
Regarding our most frequent use case described earlier, we have two filters globally configured.
Automatic Retry Filter
The AutomaticRetryAttribute is a built-in filter attribute, which handles the retry behaviour of failed jobs. In our case we don’t want any automatic retries, so we set the number of attempts to zero. We can also decide, whether Hangfire should handle this silently, but we like to have at least a message, so we log the event. But we are not further interested in these jobs, due to our clean up jobs, so we delete the failed job instances.
You can find the usage in the demo project in the ServiceRegistry extension class or read more in the Hangfire API reference.
Skippable Disable Concurrent Execution Filter
Besides the rather unwieldy name, this is the main filter in our use case. It consists of two parts; first, the “disable concurrent execution” part and second, the “skipping” part. As mentioned, our recurring jobs schedule workers for processing, thus not being allowed to run concurrently, while the workers should run in parallel.
For the first part, we let Hangfire do their resource locking by applying the built-in DisableConcurrentExecutionAttribute to, well, disable concurrent execution of the job. This filter takes a timeout and when a job is scheduled to run, it tries to acquire a resource lock. In case it doesn’t get this in the allotted time, it will throw a DistributedLockTimeoutException. This will fail the job, and I leave it as an assignment for the reader to handle it gracefully. But before letting the filter perform, our wrapper checks if a certain parameter is set on the context, which allows to skip this filter.
Setting this parameter is the second part, handled by a different filter. Only is this filter directly applied to the job method and not configured globally. Of course, running multiple workers in parallel comes with all the ups and downs of processing data concurrently, so be vigilant.
You can find an example usage in the demo project in the DynamicConcurrencyBatchJob.
Addition: Preserve Original Queue Filter
We don’t use this filter anymore, because like mentioned before, we don’t reschedule jobs automatically. But when we experimented with requeuing jobs, we would find them to be scheduled in the default job queue, instead of the queue they were originally assigned to. Which could lead to the wrong server picking it up and running into an error.
This filter simply ensures the same queue is set on the job as it was when first scheduled. You can find an implementation here.
Storage
Hangfire can create the database tables it needs on its own. We don’t think it’s good practice to let an application have the necessary rights to alter the database structure, even though we separated them into their own schema. Thus, we connected to a test database and copied the schema from there. I imagine there are better ways to do this, since we ran into the issue of missing an index. And because Hangfire uses table hints like "FORCESEEK" for its queries, these are definitely required. After the setup worked, it wasn’t feasible look further into this, though.
We also just ran some trivial tests to analyze the load Hangfire generates on the database. For our storage solution it was negligible, but with the serialization and polling, I would recommend running some benchmarks first especially for read/write sensitive cloud databases.
Conclusion and Future Work
I recall thinking that the documentation appeared to be a little dated and was confusing for me at first, particularly the “Getting Started” section with its differentiation of ASP.NET and ASP.NET Core. But that’s not entirely their fault, I guess. – Looking at you, MS – The core principles are considerably basic, which contributes to the framework running reliably. It is also painless to customize and straightforward to configure. We have had good experiences with it in last few years.
The demo project is knowingly kept basic. For a more sophisticated setup, e.g. in a containerized environment, it needs to be further evaluated whether Hangfire is viable for your use case. An orchestration platform, e.g. Kubernetes, might be able to schedule and manage jobs itself. But they could also work hand in hand. Say, we split the job scheduling via client from the server execution and apply a horizontal autoscaler to the server pod. It could then spin up multiple server instances depending on the current load of your application.
Thanks for reading and happy processing!